Building Real-Time Data Pipelines with Kafka and Spark
Learn how to design and implement scalable real-time data pipelines using Apache Kafka and Spark Streaming for high-throughput event processing.
Building Real-Time Data Pipelines with Kafka and Spark
In today's data-driven world, the ability to process and analyze data in real-time has become crucial for businesses to stay competitive. Real-time data pipelines enable organizations to make instant decisions, detect anomalies as they occur, and provide immediate insights to stakeholders.
Architecture Overview
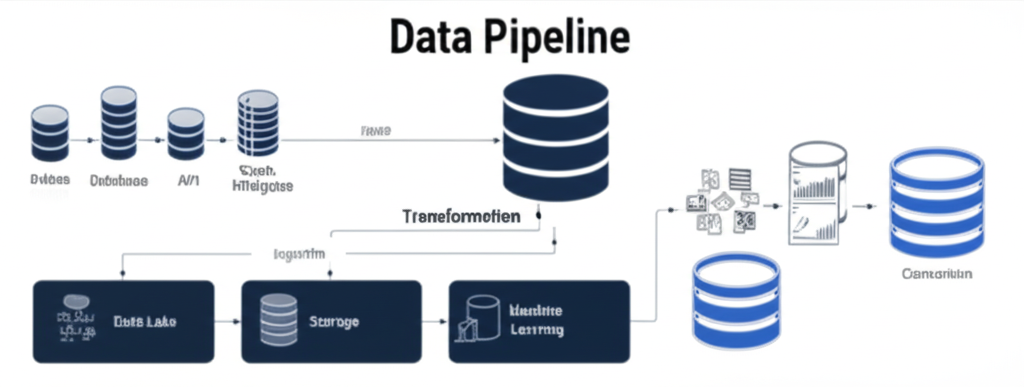
A robust real-time data pipeline typically consists of several key components:
1. Data Ingestion Layer
- Apache Kafka: Acts as the central nervous system for data streaming
- Schema Registry: Ensures data consistency and evolution
- Kafka Connect: Simplifies integration with various data sources
2. Stream Processing Layer
- Apache Spark Streaming: Processes data in micro-batches
- Structured Streaming: Provides exactly-once processing guarantees
- Custom transformations: Business-specific data processing logic
3. Storage Layer
- Data Lake: For long-term storage and batch analytics
- Real-time databases: For immediate query access
- Caching layer: For ultra-low latency requirements
Implementation Best Practices
Kafka Configuration
``` val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "localhost:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "spark-streaming-consumer", "auto.offset.reset" -> "latest", "enable.auto.commit" -> (false: java.lang.Boolean) ) ```
Spark Streaming Setup
``` val spark = SparkSession.builder() .appName("RealTimeDataPipeline") .config("spark.sql.streaming.checkpointLocation", "/tmp/checkpoint") .getOrCreate()
val df = spark .readStream .format("kafka") .options(kafkaParams) .load() ```
Performance Optimization
- Partitioning Strategy: Ensure optimal data distribution
- Batch Size Tuning: Balance latency and throughput
- Resource Allocation: Right-size your cluster
- Monitoring: Implement comprehensive observability
Conclusion
Building real-time data pipelines requires careful consideration of architecture, technology choices, and operational practices. With the right approach, you can achieve sub-second processing latencies while maintaining high reliability and scalability. ```
Let's create a utility function to help with image paths: