Deploying Kubernetes Operators for Scalable Data Pipelines
Learn how to leverage Kubernetes Operators to automate the deployment and management of complex data pipeline components.
1 min read
Cloud Architect

Deploying Kubernetes Operators for Scalable Data Pipelines
Kubernetes Operators enable you to extend the cluster's capabilities by encoding domain-specific knowledge into custom controllers.
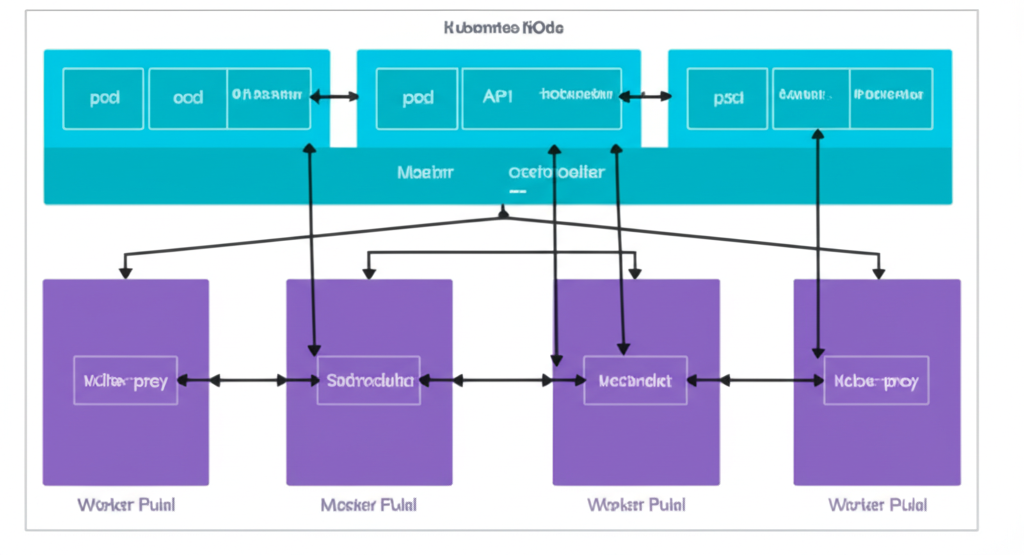
Kubernetes cluster diagram
Operator Pattern
Operators build on custom resources to manage stateful applications. They watch the Kubernetes API and reconcile the cluster to the desired state.
Example CRD
apiVersion: datapipeline.example.com/v1 kind: KafkaCluster metadata: name: ingestion-cluster spec: replicas: 3
Benefits
- Automation: Complex upgrades and failovers become repeatable.
- Consistency: Operators enforce best practices across environments.
- Scalability: New pipeline components are spun up with minimal manual intervention.
Conclusion
By packaging operational knowledge in an Operator, teams achieve robust, self-healing data pipelines that scale with workload demands.