Building a Real-Time Data Pipeline from Kafka to Snowflake
Table of Contents
- So What is Confluent Kafka?
- Architecture Overview
- Setting Up the Kafka Data Ingestion
- Transforming Data with ksqlDB (KSQL Streams)
- Streaming and Batch Loading Data into Snowflake
- Conclusion
1. So What is Confluent Kafka? 🤔
Building a real-time data pipeline with a self-hosted version of Kafka can seem a little scary, but platforms like Confluent make it super easy to setup a streaming pipeline within minutes. In this tutorial I will guide you through setting up a streaming pipeline where data flows from a source into Kafka, gets processed by ksqlDB (Kafka’s SQL engine), and it is then delivered into Snowflake in near real-time.
NOTE: This tutorial assumes that you have a basic understanding of Apache Kafka.
Confluent Kafka is an deployment distribution of Apache Kafka. Basically it provides a fully managed platform for real-time data streaming.
At its core, Apache Kafka is a distributed event streaming platform used to build real-time pipelines and applications.
Kafka is designed in a way that it can handle large volumes of data with high throughput and low latency, making it ideal for use cases like real-time analytics, log collection, and event-driven microservices.
But why do we need to use Kafka at all? 😬 The beauty of Kafka lies in it's scalability and fault tolerance. Data is replicated across brokers to prevent loss, and topics can be partitioned for parallel processing.
In short, Confluent Kafka is Kafka made easier: it keeps Kafka’s core strengths in handling real-time streams, while also getting a user-friendly, cloud-based experience for setup and monitoring.
Before we move further, let's understand some terms that I am going to be using frequently:
-
Connectors: A library of pre-built source and sink connectors that make integration with external systems (S3, Snowflake, Postgres etc.) in a scalable, fault-tolerant way.
-
ksqlDB (Kafka SQL): A SQL-like stream processing engine that allows us to create real-time transformations and aggregations on Kafka topics using simple SQL statements. Kafka's flavor of SQL.
-
Schema Registry: A centralized registry for data schemas (Avro, JSON Schema, Protobuf) that ensures producers and consumers share a consistent data format and handle schema evolution safely. This prevents data compatibility issues as your schemas evolve over time.
2. Architecture Overview
Let’s start with a high-level view of the streaming pipeline we’re building. The data flows through several stages:
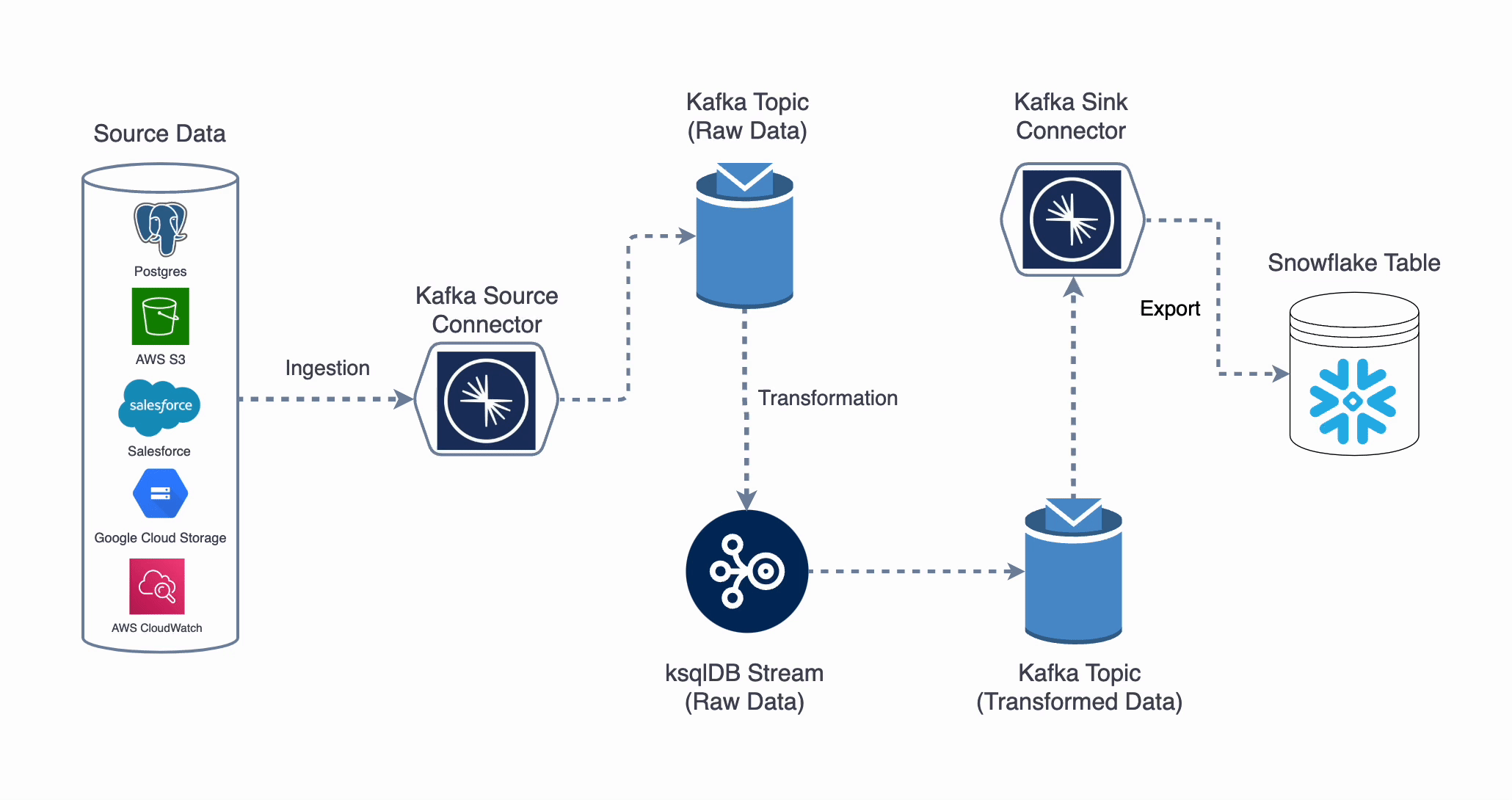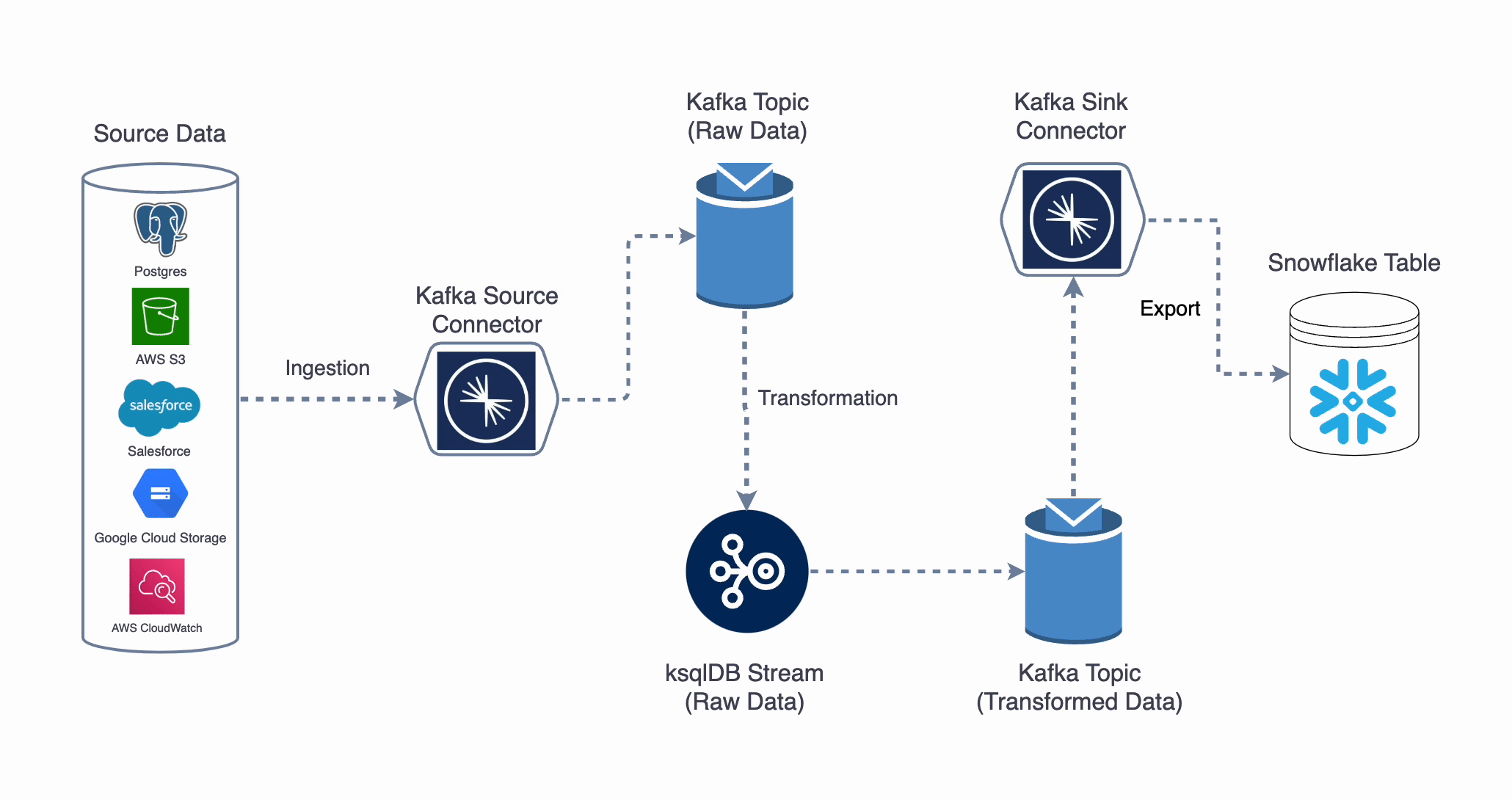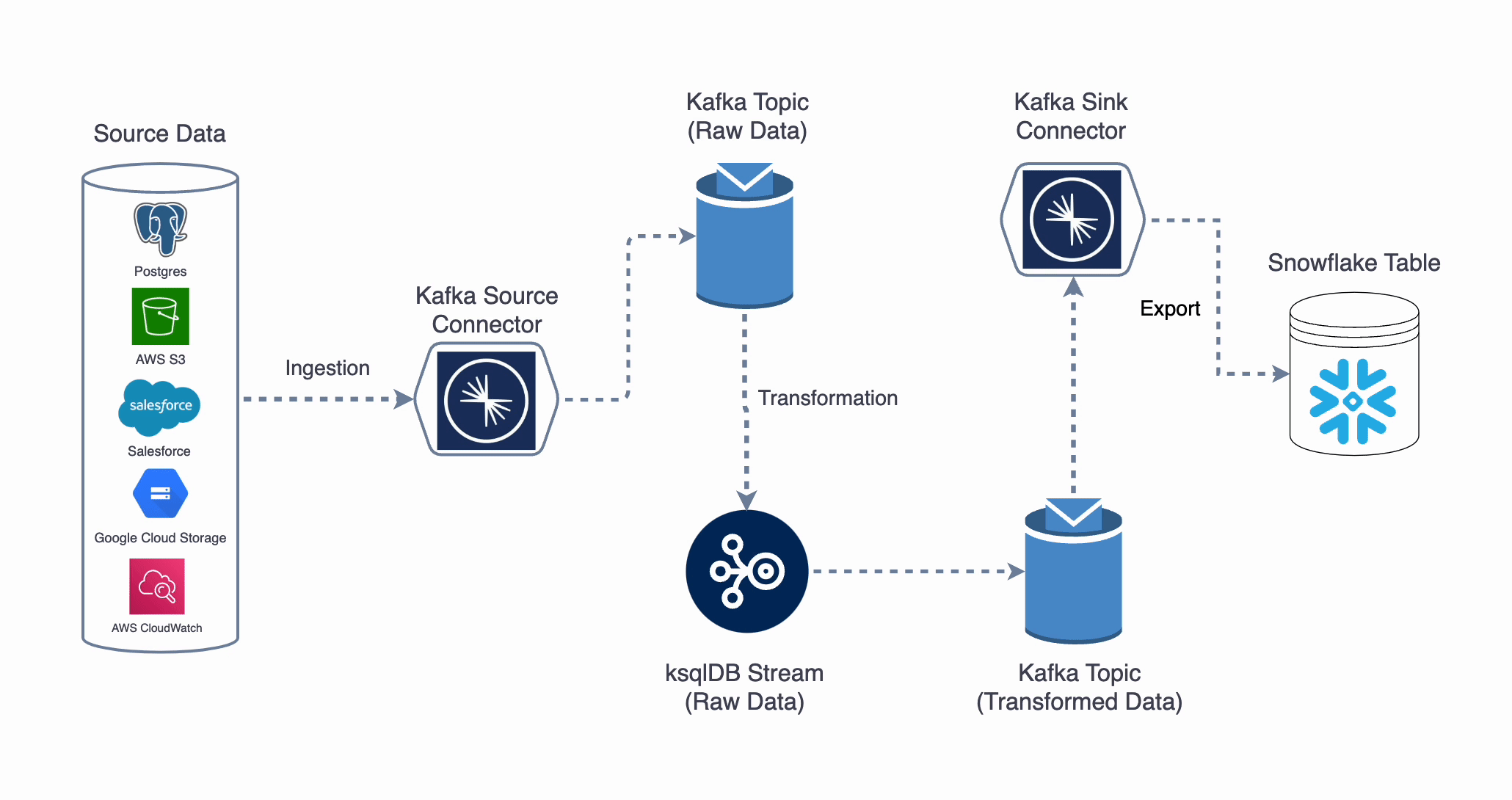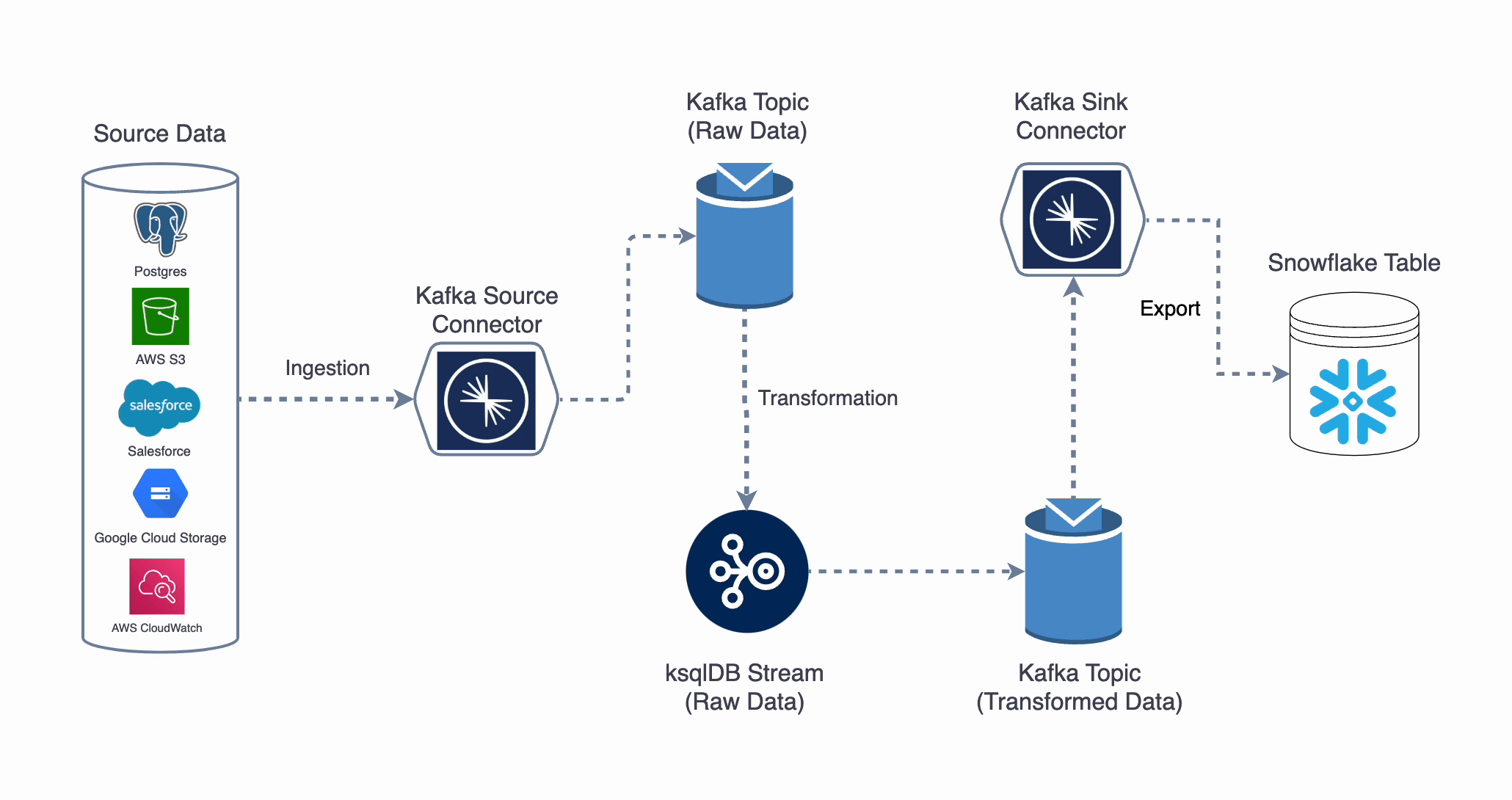
Kafka to Snowflake: Streaming Data Pipeline
In this pipeline, Confluent Kafka acts as the central data stream hub, and Snowflake is the destination data warehouse. Here’s what each component does:
-
Source Data: The journey of our data starts here. It could be application logs, IoT sensor readings, database changes, etc. In this tutorial, I'll be using Confluent’s Datagen connector (which generates mock data).
-
Kafka Source Connector: The Datagen source connector will publish streaming events to a Kafka topic for us. You could replace this with a connector for real systems (e.g., a JDBC connector for databases, CDC tools for capturing changes, etc.).
-
Kafka Topic (Raw Data): A Kafka topic is like a feed or stream where messages on the same subject are stored. The raw events from the source are written to a Kafka topic. These topics are partitioned for scalability and can retain data for a configurable period. (We can select the number of partitions but the default is 6)
-
ksqlDB Stream (Real-Time Transformation): ksqlDB will read from the raw Kafka topic, apply SQL-defined transformations (such as filtering unwanted events, aggregating data, etc.), and write the results to another Kafka topic. Essentially, ksqlDB allows us to create derived streams or tables in Kafka through SQL queries.
-
Kafka Topic (Transformed Data): This is the Kafka topic that receives the processed data (output of our ksqlDB queries). It is the data we will finally send to Snowflake.
-
Snowflake Sink Connector: A Kafka connector that continuously reads from the transformed Kafka topic and writes the data into Snowflake. It acts as a bridge between Kafka and Snowflake, batching the stream or using Snowflake’s streaming API to load data with low latency.
-
Snowflake Table: The final table in Snowflake where the streaming data lands.
This architecture decouples data producers from consumers: Kafka is the buffer and distributor of data, ksqlDB is the real-time processing engine, and Snowflake is the storage and query engine.
3. Setting Up the Kafka Data Ingestion
To get data flowing into Kafka, we’ll use Confluent Cloud (Kafka as a service) and the fully-managed Datagen Source Connector.
Create a Kafka Cluster
Create a Kafka Cluster on Confluent Cloud (if you don’t have one).
Select the Cluster Type, Provider, Region and Uptime SLA based on your requirements.
You can choose to create the cluster on a private network but it makes life a lot more difficult when you decide to try out Cluster Linking.

Create a Kafka Connector
In the Confluent Cloud interface, add a Source Connector and choose “Sample Data”. This connector will continuously generate events based on a predefined schema or template. You’ll need to configure a few key parameters (detailed next).
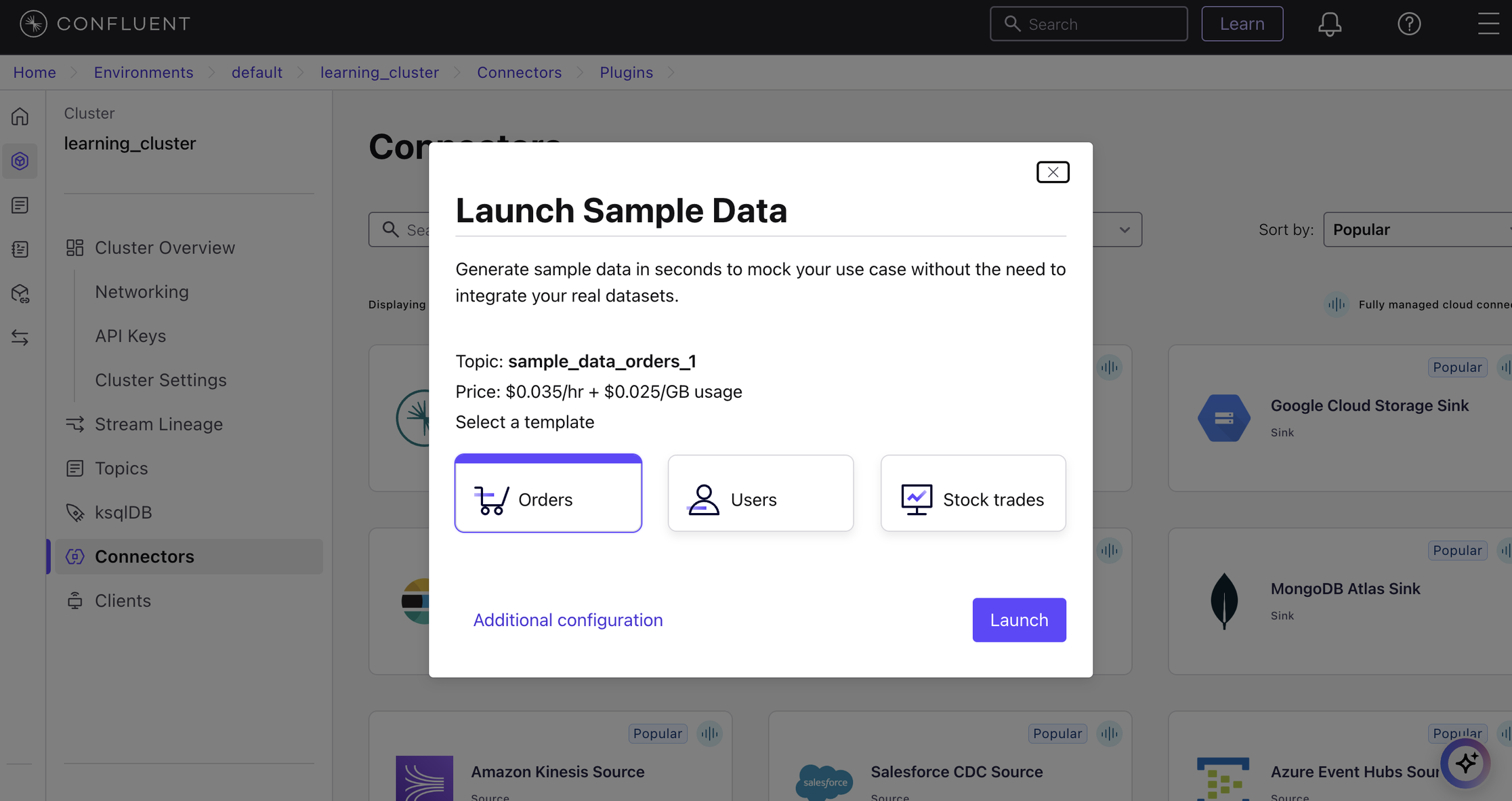
Step-by-Step Connector Configuration:
- Data Generation Template: Choose a sample data model (e.g., orders, pageviews, financial).
- Connector Name: Give it a descriptive name (e.g., orders-datagen-connector).
- API Key: Use an API key you generated previously or generate a new one.
- Input Message Format: Choose the format (JSON, Avro, Protobuf).
- Output Record Format: Select JSON_SR (requires Schema Registry).
- Output Topic: Specify the Kafka topic (e.g., orders_raw).
- Enable Connector Auto-restart: Recommended.
Example Message:
{
"ordertime": 1505461992786,
"orderid": 27358,
"itemid": "Item_7",
"orderunits": 9.315348659866387,
"address": {
"city": "City_",
"state": "State_24",
"zipcode": 56096
}
}
4. Transforming Data with ksqlDB (KSQL Streams)
Raw data is often not immediately useful without some transformation. ksqlDB (KSQL) allows us to create streaming transformations on Kafka data using SQL syntax.
Create a ksqlDB Cluster
Before creating your ksql streams you will have to create a ksqlDB cluster. The process is extremely straightforward. Just enter the name of your cluster and cluster size depending on your workload and your are good to go!
Create a ksql Streams
ksqlDB treats Kafka topics as tables or streams depending on use-case. In our scenario, we’ll create a stream for the raw topic. For example, if our raw topic is sample_data_orders, we can define a ksqlDB stream on top of it:
CREATE STREAM orders_stream (
order_id VARCHAR,
customer_id INT,
state VARCHAR,
total_amount DOUBLE,
order_time VARCHAR
) WITH (
kafka_topic = 'sample_data_orders',
value_format = 'JSON_SR',
partitions = 3
);
Here we specify the schema (field names and types) and that the data format is JSON_SR (JSON with Schema Registry). Note: Since the topic has an associated schema in Schema Registry, ksqlDB can also fetch the schema automatically; you could alternatively use VALUE_FORMAT='JSON_SR' without listing columns and let ksqlDB infer the schema. In any case, we now have orders_stream as a ksqlDB representation of the incoming data.
Filtering Stream Data (Stateless Transformation)
Suppose we only want to pass through high-value orders to Snowflake (because anything below $1000 is not worth searching for😂). We can create a derived stream with a filter condition:
CREATE STREAM high_value_orders AS
SELECT *
FROM orders_stream
WHERE total_amount > 1000;
This statement does two things:
- It creates a new Kafka topic (often with the same name as the stream, here
HIGH_VALUE_ORDERS) - Continuously writes to it only those events from
orders_streamthat meet the WHERE condition.
The process is stateless – each order event is evaluated independently. If the order’s total_amount is greater than 1000, it is passed along; otherwise, it is dropped. This is similar to a WHERE filter in SQL on a static table, except here it’s continuous. As Confluent’s example shows, you can filter a stream like ORDERS to create a subset stream (e.g., orders from New York) using a similar CREATE STREAM ... AS SELECT ... WHERE ... clause (Filtering a ksqlDB Stream into a New Stream). Under the hood, ksqlDB creates a new Kafka topic for high_value_orders, and any consumers (like our Snowflake connector later) can just read from that topic to get already-filtered data. In fact, if we list Kafka topics now, we’d see an entry for this new stream, since ksqlDB streams are backed by Kafka topics.
Aggregating Stream Data (Stateful Transformation)
KSQL can also perform aggregations, which are stateful operations (meaning they require maintaining some state from previous events). For instance, perhaps we want to keep a real-time count of orders per state (to see how many orders each region is placing). We can do:
CREATE TABLE orders_by_state AS
SELECT state, COUNT(*) AS order_count
FROM orders_stream
GROUP BY state
EMIT CHANGES;
This will create a table (backed by a Kafka topic, often a compacted topic since it’s an aggregate) that updates counts per state whenever new orders come in. The COUNT(*) aggregation is stateful because to compute a running count, ksqlDB must store and update the count for each state as new events stream in. Similarly, any aggregation, windowing (like a 5-minute rolling average), or joins between streams will be stateful.
Stateless vs Stateful Transformations:
-
Stateless operations do not depend on any history – each event is processed independently. Examples: filtering (WHERE clauses), projecting/selecting certain fields, simple transformations (like converting units, or computing a value from a single event). These do not require storing any past data. You input a record, you output a record (or drop it) purely based on that record’s content.
-
Stateful operations depend on the accumulated state from many events. Examples: aggregations (COUNT, SUM, AVG over time or grouped data), windowed operations, or joins (which need to match events from one stream with another). These require maintaining context – e.g., a counter, a sum, or a buffer of events to join. In our pipeline, the filter for high-value orders is stateless (each order is considered by itself), while counting orders by state is stateful (the count for a given state builds over time with each order).
“In a nutshell, stateful operations are dependent on previous events of the stream, whereas stateless operations are not.”
For this tutorial, our goal is simply to filter and maybe do a light transformation. We’ll proceed with the high_value_orders stream as the data we want in Snowflake. You could further transform it using additional KSQL queries. The nice thing about ksqlDB is you can chain these transformations—each resulting stream/topic can be consumed by another query or by external consumers. And everything is real-time: as soon as an event meets the condition, it’s available in the output stream typically within milliseconds.
Before moving on, here’s a quick example of a ksqlDB transformation query and its result:
- Input Stream (orders_stream): contains all orders.
- Transformation (stateless filter):
CREATE STREAM high_value_orders AS
SELECT * FROM orders_stream
WHERE total_amount > 1000;
- Output Stream: a Kafka topic
HIGH_VALUE_ORDERSthat now only has orders wheretotal_amount > 1000. This output is continuously updated as new orders come in.
5. Streaming and Batch Loading Data into Snowflake
Confluent provides a Snowflake Sink Connector that pulls data from Kafka and inserts it into Snowflake.
Configuring the Snowflake Sink Connector
To set up the Snowflake Sink Connector in Confluent Cloud:
- Snowflake Connection Info: Provide your Snowflake account URL, User Name, and Private Key. (Read about generating Private Key for a role in Snowflake here)
- Target Database, Schema, and Table: Specify the Snowflake
database.schema.tablewhere data should be ingested. The connector can auto-create the table based on the Kafka topic name. - Kafka Topics to Ingest: List the Kafka topic(s) to pull data from. Ensure the topic exists.
- Data Format and Converters: Choose Avro, JSON Schema, Protobuf, or raw JSON as the input format. Since we use JSON_SR, Confluent’s JSON Schema Converter should be selected.
- Snowflake Ingestion Mode:
- Snowpipe (Batch, Default): Buffers messages and writes them in micro-batches via Snowpipe, introducing minimal delay (few second to few minutes).
- Snowpipe Streaming (Continuous): Uses Snowflake’s Streaming API for near real-time ingestion, avoiding batch overhead (Sub-second delay).
- buffer.count.records: Maximum records per batch (e.g., 10,000).
- buffer.size.bytes: Maximum batch size (e.g., 5 MB).
- buffer.flush.time: Time-based flush (e.g., 60 seconds).
- Parallelism and Scaling: Configure
tasks.maxto match the number of topic partitions for efficient parallel ingestion.
Batch vs. Streaming Ingestion
- Snowpipe Batch is efficient for large batches but incurs per-batch cost.
- Snowpipe Streaming is more cost-effective for high-frequency, continuous data.
Deploying the Connector
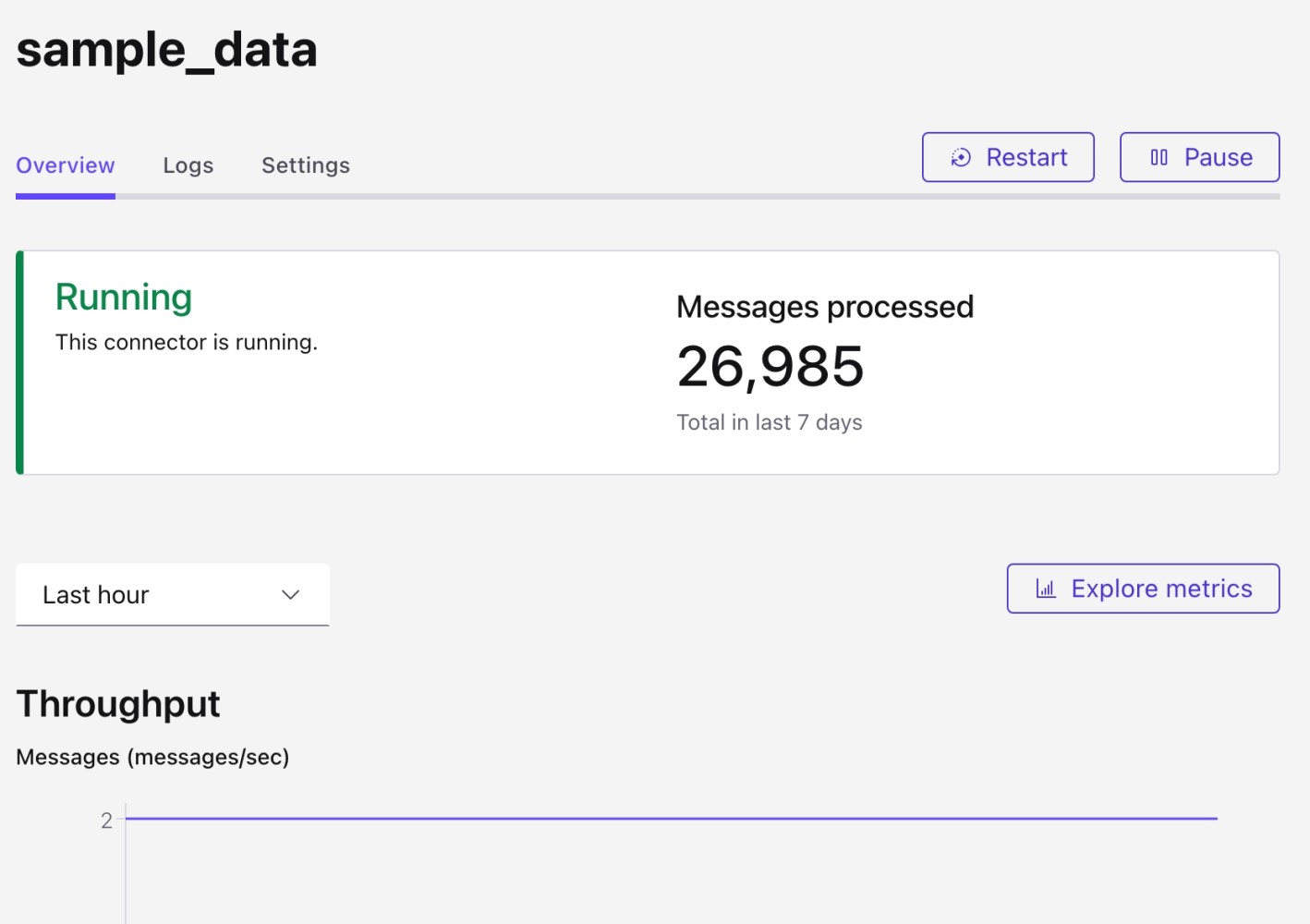
After configuring the connector, launch. Monitor its status in Confluent UI and verify that data is landing in Snowflake.
Conclusion
This completes the Kafka-to-Snowflake data pipeline. In this tutorial, we set up a basic real-time pipeline, generated sample data, ingested it into Kafka, processed it in motion with ksqlDB, and delivered it to Snowflake for storage.
If you found this guide helpful, follow me for more deep dives into data engineering! Feel free to like, comment, or share your thoughts - I’d love to hear how you’re using Kafka in your projects. Happy Streaming 🚀